빅데이터분석필기[1과목] 빅데이터 분석 기획 - 3.데이터 수집 및 저장 계획
1.3 데이터수정및 저장계획
* 데이터구조적 분류 - 정형데이터, 비정형 데이터, 반정형 데이터 (실시간데이터는 존재형태로 분류)
1. 정형데이터 - 고정된 구조로 정해진 필드에 저장된 데이터를 의미 , 엑셀,csv, RDBMS 가 대표적
2. 비정형데이터(외부데이터) - 정해진 구조가 없는 데이터, 동영상, 소셜네트워크 댓글, 위치데이터등, 크기가 크고 복잡
3. 반정형데이터 - 데이터와 메타데이터, 스키마 등을 포함하는 데이터를 의미 , XML, HTML, JSON 이 대표적
* 데이터 수집방법
* 데이터 유형에 따른 수집방법
| 유형 | 정형 데이터 | 비정형 데이터 | 반정형 데이터 |
| 방법 | -ETL: 추출, 변환, 적재 -FTP: 파일 송수신 프로토콜 -API: 실시간 데이터 수신 인터페이스 -DBToDB: 데이터베이스간 동기화 -Rsync: 일대일 동기화 -Sqoop: RDBMS와 하둡간 데이터 전송 |
-크롤링: 웹사이트에서 데이터수집 -RSS: XML기반 프로토콜 활용 -Open API: 실시간 데이터 수신 -스크래파이: 파이썬 기반 크롤링 -아파치 카프카: 데용량 실시간 로그 처리 |
-센싱: 센서 데이터 -스트리밍: 미디어 실시간 수집 -플럼: 분산형 대량 로그 수집 기술 -스크라이브: 대량 실시간 로그 수집 기술 -척와: 대규모 분산 시스템 모니터링 |
1. 정형 데이터 수집 방식 및 기술: ETL, FTP, API, DBToDB, Rsync, Sqoop
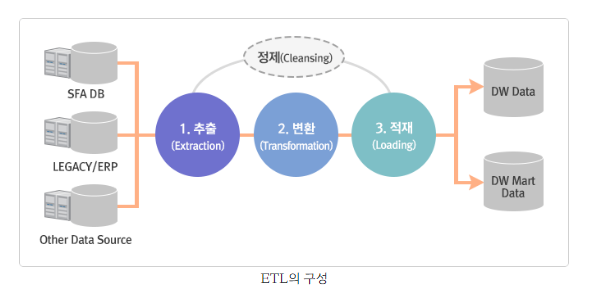
* ETL: 추출(Extract), 변환(Transform), 적재(Load)
데이터 조회 , 분석을 목적으로 적절한 구조로 추출, 변환, 적재하는 작업 기술로 데이터를 데이터 저장소인 데이터 웨어하우스 DW() 및 데이터 마트(DM)에 이동시키기위한 작업 및 기술
*데이터 웨어하우스(Data Warehouse)
- DB 축적된 데이터를 공통 형식으로 변환해서 관리하는 저장소
- 여기서 관리하는 데이터들은 시간의 흐름에 따라 변화하는 값을 유지한다
* 데이터 마트(Data Mart)
- DW에서 데이터를 꺼내 사용자에게 제공함
- 특정 사용자가 관심을 가지고 있는 데이터를 담은 비교적 작은 규모의 데이터 웨어하우스(DW)
- 재무/ 생산/ 운영 등과 같이 특정 조직의 특정 업무 분야에 초점을 맞추어 구축
* FTP: File Transfer Protocol, 파일 송수신 응용계층 통신 프로토콜
- 원격지 시스템 간 파일 공유를 위한 서버-클라이언트 모델
- TCP/IP 프로토콜을 기반으로 서버, 클라이언트 사이에서 파일 송수신
- Active FTP: 클라이언트가 포트를 알려주면 데이터 전송해주는 방식(서버가 자신의 20번 포트를 통해 클라이언트의 임의의 포트로 데이터를 전송해주는 방식 , 명령은 21번 포트, 데이터는 20번 포트 를 사용
- Passive FTP: 서버가 포트를 알려주면 클라인어트가 데이터 가져가는 방식(명령은 21번포트 , 데이터는 1024이후의 포트 사용)
* API: Application Programming Interface, 실시간 데이터 수신 기능을 제공하는 인터페이스 기술
솔루션 제조사 및 3rd party 소프트웨어로 제공되는 도구
* DBToDB: 데이터베이스 시스템 간 데이터 동기화 및 전송 기능
* Rsync: Remote Sync, 서버-클라이언트 방식, 수집 대상 시스템과 일대일로 파일 및 디렉터리를 동기화
* 스쿱(Sqoop): 커넥터를 사용하여 RDBMS와 하둡(HDFS) 간 데이터 전송 , 전송, 수집 등 모든 적재 과정이 자동화
- 벌크 임포트 지원(전체 데이터베이스 또는 테이블을 한번에 전송)
- 데이터 전송 병렬화
- 직접입력 제공(RDB에 매핑해서 HBASE 와 HIVE에 직접 IMPORT)
- 프로그래밍 방식의 데이터 인터렉션(자바 클래스 생성을 통한 데이터 상호작용 )
- Import(가져오기), Export(내보내기), Job(생성 및 실행) Metastore, Merge(데이터셋 병합)

2. 비정형 데이터 수집 방식 및 기술: 크롤링, RSS, Open API, 스크래파이, 아파치 카프카
* 크롤링(Crawling): 웹 사이트로부터 웹문서, 컨텐츠를 수집
* RSS(Rich Site Summary): 블로그 , 뉴스, 쇼핑몰등의 웹사이트에 게시된 새로운 글을 공유하기위해 XML 기반으로하는 정보를 배포하는 프로토콜을 활용하여 수집하는 기술
* Open API: 응용 프로그램을 통해 실시간 데이터 수신
* 스크래파이(Scrapy): Python 기반 비정형 데이터 수집 기술
- 웹 사이트를 크롤링하여 구조화된 데이터 수집
- 주요기능:
- Spider : 크롤링 대상 웹사이트 및 웹페이지의 어떤부분을 스크래핑 할것인지를 명시하는기능
- Selector: 웹페이지의 특정 HTML 요소를 선택하는 기능 (LXML 기반으로 제작가능)
- Items : 웹페이지를 스크랩하여 저장할떄 사용되는 사용자 정의 자료 구조
- Pipelines: 스크래핑 결과물을 아이템형태로 구성할때 가공하거나 파일형태로 저장 제공기능
- Settings: Spider와 Pipeline 을 동작시키기위한 세부설정
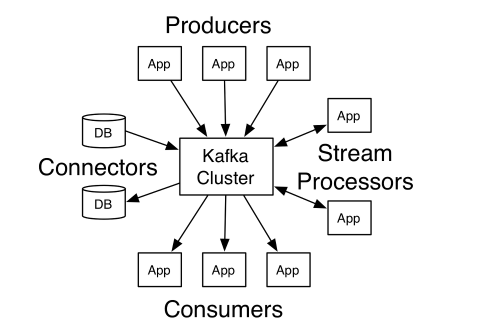
* 아파치 카프카(Apache Kafka): 대용량 실시간 로그 처리를 위한 분산 스트리밍 플랫폼
- 레코드 스트림을 발행, 구독하는 방식(기존 메시징 시스템과 유사)
- 특징: 신뢰성(메모리및 파일 큐 기반의 채널지원), 확장성 제공(Multi Agent, Consolidation, Fan Out Flow 방식으로 수평 확장 및 분산 처리 가능)
- 주요 기능: 소스(Source-수집영역), 채널(Channael -소스와 싱크간 버퍼구간), 싱크(Sink-전달 및 저장), 인터프리터(Interpreter - 가공)
3. 반정형 데이터 수집 방식 및 기술: 센싱, 스트리밍, 플럼, 스크라이브, 척와
* 센싱(Sensing): 네트워크를 통해 센서데이터 수집& 활용
* 스트리밍(Streaming): 네트워크로 미디어 데이터를 실시간 수집(센서, 오디오, 비디오 등)
* 플럼/스크라이브/척와의 활용은 점차 증가하는중
* 플럼(Flume): 분산형 대용량 로그 수집 기술로 이벤트와 에이전트 활용
- 발행/구독 모델: 메세지 큐와 유사한형태의 데이터큐를 사용, 풀(Pull) 방식으로 부하 감소, 고성능 기능 제공
- 고가용성(High Availiability) 제공: 클러스터 구성, 분산 처리를 통해 고가용성 서비스 제공 가능
- 파일 기반 저장방식: 데이터를 디스크에 순차 저장
- 주요 기능: 소스(Source -이벤트를 전달하는 컨테이너, 소스,채널,싱크로 흐름제어), 채널(Channel - 이벤트 를 소스와 싱크로 전달 통로), 싱크(Sink -채널로부터 받은 이벤트 저장 및 전달)

* 풀(Pull)방식 - 사용자가 자신이 원하는 정보를 요청할 때, 서버에서 정보를 전송하는 기법
(푸시(Push) 방식은 반대로, 사용자가 요청하지 않아도 자동으로 원하는 정보를 제공하는 기법)
* 스크라이브(Scribe): 대용량 실시간 로그 수집 기술
- 다수의 서버로부터 실시간 스트리밍 로그 데이터를 수집하여 분산 시스템에 저장
- 다양성: 클라이언트 서버 타입에 상관없이 로그 수집 가능
- 고가용성: 단일 중앙 서버 장애 → 다중 로컬 서버에서 저장
- 단일 중앙 스크라이브 서버와 다수의 로컬 스크라이브 서버로 구성되어 안정성과 아파치 Thrift 기반 스크라이브 API를 활용하여 확장성을 제공
* 고가용성 (HA) - 서버와 네트워크 , 프로 그램의 정보시스템이 시스템의 장애에 대응해서 오랜기간동안 지속적으로 정상운영이 가능한상태를 만드는환경
* 척와(Chukwa): 대규모 분산 시스템 모니터링을 위한 에이전트-컬렉터 구성의 데이터 수집 기술
- 분산된 서버에서 에이전트 실행 → 컬렉터가 데이터 수집 → HDFS에 저장 및 실시간 분석 기능 제공
- 특징: HDFS 연동, 실시간 분석, 청크(Chunk) 단위 처리 (어댑터가 데이터를 메타데이터가 포함된 청크단위로 전송)
- 구성: 에이전트(데이터 수집, 페일오버기능으로 데이터유실방지), 컬렉터(데이터를 주기적으로 HDFS에 저장)
- 데이터 처리: 아카이빙(Archiving, 시간 순서로 그룹핑,HDFS Sequence File 포멧으로 저장), 디먹스(Demux, 키-값 쌍으로 척와레코드 생성 및 파일로 저장)
- 척와는 비정형, 반정형 데이터 수집 둘 다 사용

* 청크 (Chunk) - 파일이 나누어진 조각의 단위
* 페일오버 (Fail Over) - 컴퓨터 서버, 시스템 네트워크 등에서 이상이 생겼을때 예비시스템으로 자동전환되는 기능
* 시간 관점에 따른 수집 방법 : 실시간, 비실시간
- 시간 관점 또는 활용 주기에 따라 분류한다
- 실시간 데이터: 생성된 이후 수 초 ~ 수 분 이내에 처리되어야 의미있는 현재 데이터
- 센서 데이터, 알람, 시스템 로그, 네트워크 장비 로그, 보안 장비 로그
- 비실시간 데이터: 생성된 이후 수 시간 or 수 주 이후에 처리되어야 의미있는 과거 데이터
- 통계, 웹 로그, 서비스 로그, 구매 정보, 디지털 헬스케어 정보
* 저장 형태 관점
- 파일, 데이터베이스, 콘텐츠, 스트림 데이터
- 파일 데이터: 파일 형식으로 저장, 크기가 대용량 or 개수가 다수인 데이터
- 데이터베이스 데이터: 데이터 종류 or 성격에 따라 데이터베이스의 컬럼 또는 테이블 등에 저장된 데이터
관계형 데이터베이스(RDBMS), NoSQL, 인메모리 데이터베이스
- 콘텐츠 데이터: 개별적 객체로 구분될 수 있는 미디어 데이터
텍스트, 이미지, 오디오, 비디오 등
- 스트림 데이터: 네트워크를 통해 실시간 전송되는 데이터
센서 데이터, HTTP 트랜잭션, 알람 등
* 데이터 처리기술: 필터링/ 변환/ 정제/ 통합/ 축소
| 기술 | 필터링 | 변환 | 정제 | 통합 | 축소 |
| 설명 | 목적에 맞지 않는 정보 - 보정/ 삭제/ 중복성 등 |
일관성 있는 형식 - 평활화/집계/정규화 등 |
불일치성 교정 - 결측값/ 잡음 처리 등 |
출처 다름, 상호연관성 있는 데이터 결합 |
불필요한 데이터 축소 고유한 특성은 손상 X |
* 데이터 수집 프로세스: 수집데이터 도출 - 목록작성 - 소유기관 파악&협의 - 데이터 유형분류&확인
- 수집기술 선정 - 수집주기 결정 - 수집실행
* 수집 데이터의 대상 : 내부 데이터 - 서비스/ 네트워크/ 마케팅 , 외부 데이터 - 소셜/ 네트워크/ 공공
| 유형 | 내부 데이터 - 주로 정형 데이터 | 외부 데이터 - 주로 비정형 데이터 | ||||
| 대상 | 서비스 | 네트워크 | 마케팅 | 소셜 | 네트워크 | 공공 |
| 종류 | - SCM/ ERP/ CRM - 인증/ 거래시스템 - 포털 등 |
- 백본/ 방화벽 - IPS/ IDS - 스위치 등 |
- VOC 접수 데이터 - 고객 포털 시스템 |
- SNS - 게시판 - 커뮤니티 등 |
- 센서 데이터 - 장비간 발생로그 (M2M) 등 |
정부에서 공개한 공공 데이터 (LOD) |
* ERP - 전사적자원관리 - 회사의 모든정보 , 프로세스 통합 관리 시스템
* SCM - 공급망관리 - 물류, 유통, 원재료 수급에서 생산까지 관리시스템
* CRM - 고객관리 - 고객 중심 자원관리, 마케팅관리 시스템
* 데이터 형태에 따른 분류
- 정성적: 언어, 문자 형태, 저장, 검색, 분석에 많은 비용 소모
- 정량적: 수치, 도형, 기호 형태, 정형화된 데이터이므로 비용 소모 적음
* 수집대상 목록 작성시 검토할 사항
- 수집가능성, 보안문제, 수집비용, 정확성, 난이도 고려
* 척도 - 척도란 수집된 데이터가 다른 데이터와 구분하기위한 특성을 의미
* 데이터는 측정방법에따라 질적자료와 양적자료 로 구분
질적자료 - 명목척도와 순위척도
양적자료 - 구간척도와 비율척도로 구분
| 데이터 속성 | |
| 명목형(범주형) Nominal |
명사형/ 이름만 의미부여 크기&순서 상관없음 |
| 순서형(범주형) Ordinal |
순서에 의미부여O (ex. 만족, 보통, 불만족) |
| 이산형(수치형) Discrete |
변수값을 하나하나 개수로 셀 수 있는 경우 |
| 연속형(수치형) Continuous |
변수가 구간내 모든값을 가질 수 있는 경우 |
| 데이터 측정척도 | |
| 명목척도 | 순위가 없는 특정범주에 존재하는 척도 기호&숫자 부여 =,!= 의 연산가능 성별, 혈액형, 거주지역 |
| 서열척도 순서(순위)척도 |
분류&서열 순서가있는 척도 비계량적 변수 관측&비교 숫자크기에 의미 <,> 비교연산가능 석차,소득수준,제품평점, 아이돌 선호도 등 |
| 등간척도 간격(구간)척도 |
동일 간격화/ 크기간 차이 비교 순서,순위는 의미 없다 비계량적 변수를 정량적 측정 절대적 원점이 존재하지않는다, (0이라고 해서 값이 없다고 할수없음) (+.-)가감연산가능 온도,지수 ,점수 |
| 비율척도 | 비율계산가능, 절대적 원점이 존재 수치형변수 측정시 주로 사용 사칙연산및 크기 비교 모두가능 (ex. 나이, 키, 거리, 소득 등) *속성 값을 연산했을 때 의미 있으면 비율 척도, 의미 없으면 등간척도 |
* 데이터 변환 기술(데이터 전처리작업) - 삭제는 없다!
| 방법 | 평활화 | 집계 | 일반화 | 정규화 | 속성 생성 | 범주화 | 데이터축소, 차원축소 |
| 특징 | - 잡음(이상치) 제거 - 추세 벗어나는 값 변환 -구간화 군집화를 통해 값변환 |
- 그룹화연산을이용하여 데이터 요약 - 속성 하나로 줄임 - 스케일 변경 |
- 특정 구간에 분포하도록 - 범용적 데이터에 적합 |
- 정해진 구간내에 분포 - 최소-최대/ Z-score - 소수 스케일링 |
- 데이터 통합을 위해 새로운 속성/특징을 만드는 방법 | -데이터통합을위해 사위레벨개념의 속성이나 특성을 이용해 일반화 | -데이터축소 :같은정보량을 가지면서 데이터 크기를 줄임 - 차원축소 :데이터 차원의 크기를 축소 |
* 정규화 기법 3가지
- 최소-최대 정규화: 최솟값 0, 최댓값 1, 다른 값을은 0과 1사이의 값으로 변환
- Z-스코어 정규화: 데이터가 평균 대비 몇 표준편차만큼 떨어져 있는지 점수화
- 이상값 문제를 피하는 정규화 전략
- 소수 스케일링: 특성값의 소수점을 이동하여 데이터 크기 조정
*데이터 비식별화
: 개인정보 일부/전부를 삭제/대체하여, 다른 정보와 결합해도 특정 개인을 식별하기 어렵도록 하는 조치*
데이터 비식별화 처리기법: 가명처리/ 총계처리/ 데이터값 삭제/ 범주화/ 데이터 마스킹
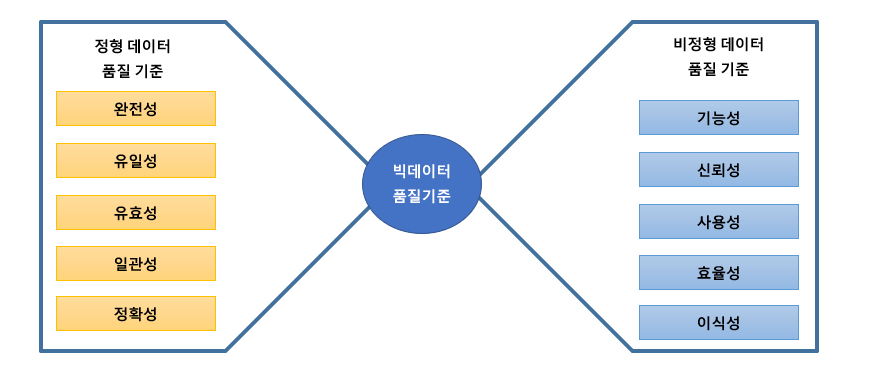
* 데이터 품질 특성 - 데이터 유효성과 활용성
- 데이터 유효성: 정확성, 일관성으로 정의함
- 데이터 정확성: 정확성, 사실성, 적합성, 필수성, 연관성
- 데이터 일관성: 정합성, 일치성, 무결성
- 데이터 활용성: 유용성, 접근성, 적시성, 보안성으로 정의함
- 데이터 유용성: 충분성, 유연성, 사용성, 추적성
- 데이터 보안성: 보호성, 책임성, 안정성
* 빅데이터 품질요소와 품질전략
| 요소 | 전략 |
| 정확성(Accuracy) | 데이터 사용 목적에 따라 데이터 정확성의 기준을 다르게 적용 |
| 완전성(Completeness) | 필요한 데이터의 완전한 확보 보다는 필요한 데이터를 식별하는 수준으로 적용가능 |
| 적시성(Timeliness) | 소멸성이 가낭 데이터에 대해 어느정도의 품질기준을 적용할것인지 결정 |
| 일관성(Consistency) | 같은 데이터 라고 할지라도 사용목적에 따라 달라지는 데이터 수집 기준때문에 데이터의 의미가 달라질수 있음 |
* 데이터 변환후 품질검증 프로세스
* 메타데이터 : 데이터에 관한 구조화된 데이터로서 다른 데이터를 설명해주는 데이터
- 수집 데이터 분석 프로세스: 빅데이터 수집 → 메타데이터 수집 → 메타데이터 분석 → 데이터 속성 분석
- 메타데이터 수집: 테이블 정의서, 컬럼 정의서, 도메인 정의서, 데이터 사전, ERD(ER-Diagram) 등
- 메타데이터를 통한 데이터 속성(유효성) 분석 방안
- 누락값 분석: NULL, 공백, 숫자 0의 분포 확인
- 값의 허용 범위 분석: 해당 속성의 도메인 유형에 따라서 범위 결정
- 허용 값 목록 분석: 허용 값 목록, 집합에 포함되지 않는 값을 발견
- 문자열 패턴 분석: 컬럼 속성값의 특성을 문자열로 도식화 → 특성을 파악하기 쉽게 해 놓은 표현 방법
- 날짜 유형 분석: DATETIME 유형, 문자형 날짜 유형을 활용
- 유일 값 분석: 유일해야 하는 컬럼에 중복이 있는지 확인
- 구조 분석: 관계 분석, 참조 무결성 분석, 구조 무결성 분석기 등을 활용하여 구조 결함 발견
* 데이터 프로파일링을 통한 품질 검증 기법
* 데이터 프로 파일링: 데이터 현황 분석을 위한 자료수집을 통해 잠재적 오류 징후를 발견하는 방법
* 절차 : 메타 데이터 수집 및 분석 -> 대상및 유형 선정 -> 프로파일링 수행 -> 프로파일링 결과 리뷰 -> 프로파일링 결과 종합
* 품질 검증 기준
- 복합성, 완전성, 유용성, 시간적요소, 일관성 , 타당성 , 정확성
- 복잡성 기준 정의: 데이터 구조, 형식, 자료, 계층 측면에서 정의함
- 완정성 기준 정의: 메타데이터, 개체 단위, 변수 정의 등을 기준으로 → 질이 충분하고 완전한가
- 유용성 기준 정의: 처리 용이성, 자료 크기, 하드웨어 및 소프트웨어의 제약 사항 측면에서 정의함
- 시간적 요소 및 일관성 기준 정의: 시간적 요소, 일관성, 타당성, 정확성을 기준으로 품질 관리
- 시간적 요소: 수집 기간, 수집 방법의 변화가 과거 자료 사용에 제약을 주는지 여부 등
*빅데이터 적재 소프트웨어 아키텍처
| 단계 | 수집 | 적재 및 저장 | 분석 | 활용 |
| - ETL - 크롤러 - 연계/수집 플랫폼 |
데이터 구성 플랫폼 - RDB저장소 - NoSQL 저장소 - Object 저장소 |
빅데이터 분석 모델/플랫폼 | - 데이터 시각화 - 데이터 활용 플랫폼 - Open-API 서비스 |
* 데이터 적재: 빅데이터 유형, 실시간 처리 여부에 따라 RDBMS, HDFS, NoSQL 저장 시스템에 적재함
* 데이터 적재 도구: 플루언티드/ 플럼/ 스크라이브/ 로그스태시
| 도구 | 플루언티드(Fluentd) | 플럼(Flume) | 스크라이브(Scribe) | 로그스태시(Logstash) |
| 설명 | - 크로스 플랫폼 오픈소스 데이터 수집 소프트웨어 - 각 서버에서 수집→중앙 전송 - 플루언티드가 로그수집에이전트 역할만 수행하는 가장 간단한 구조 |
-대용량 로그 수집/집계/이동 -실시간 스트리밍 -이벤트-에이전트 활용 |
-대용량 로그 수집 -실시간 스트리밍 -분산시스템에 데이터 저장 |
-모든 로그 정보를 수집하여 하나의 저장소에 출력해주는 시스템 |
* 빅데이터 저장 시스템: 대용량 데이터 집합을 저장&관리하는 시스템
* 빅데이터 저장기술:
분산 파일 시스템/ 데이터베이스 클러스터/ NoSQL/ 병렬 DBMS/ 네트워크 구성/ 클라우드 파일 저장시스템
| 기술 | 분산 파일시스템 | 데이터베이스 클러스터 |
NoSQL | 병렬 DBMS | 네트워크 구성 저장 시스템 |
클라우드 파일 저장 시스템 |
| 설명 | 네트워크를 통해 여러 호스트 컴퓨터 파일에 접근 |
하나의 DB를 여러개 서버상에 분산하여 구축 -데이터파티셔닝이용 |
스키마X 조인X 수평적 확장이 가능한 DBMS 특성 : BASE |
다수의 마이크로프로세서 동시에 여러개 처리 |
다른 저장장치 데이터서버 하나에 연결하여 저장 |
클라우드컴퓨팅환경 분산 파일시스템 |
| 종류 | - GFS - HDFS - 러스터 |
- 오라클 RAC - IBM DB2 ICE - MSSQL - MySQL |
- 구글 빅테이블 - HBase - SimpleDB - SSDS - Cloudata - Cassandra |
- VoltDB - SAP HANA - Verica - Greenplum - Netezza |
- SAN - NAS |
- Amazon S3 - OpenStack Swift |
* 분산 파일 시스템: 네트워크를 통해 여러 호스트 파일에 접근
| 종류 | 구글 파일 시스템 (GFS) | 하둡 분산 파일 시스템 (HDFS) | 러스터 (Lustre) |
| 특징 | 고정된크기의 청크 (64MB)들을 파일로나눔 청크&복제본을 분산 저장 |
파일크기를 블록 (128MB)로 나누어분산서버에 저장, 64에서 128MB로 증가 분산된 서버에 테라,페타 바이트 이상의 대용량 파일 저장 |
객체기반 클러스터 파일 시스템 계층화된 모듈 구조 |
| 구조 | 클라이언트가 마스터에게 파일 요정 → 마스터는 청크 서버에 요청 → 청크 서버는 클라이언트에게 청크 데이터 전송 | - 네임노드: 마스터 역할, 모든 메타데이터 관리, 데이터노드들로부터 하트비트를 받아 상태 체크 - 보조 네임노드: 상태 모니터링 보조함 - 데이터노드: 슬레이브 역할, 데이터 입출력 요청, 데이터 유실방지를 위해 블록을 3중 복제 |
- 클라이언트 , 메타데이터 서버, 객체저장서버들로 구성 -TCP/IP, 인피니티 밴드(무한대역폭)같은 네트워크 지원 |
* NoSQL 특징 -BASE:
- Basically Available - 언제든지 데이터에 접근 가능, 항상 가용성중시
- Soft-State - 노드 상태는 외부 정보로 결정됨, 특정시점에서는 일관성이 보장되지않음
- Eventually Consistency - 일정시간이 지나면 데이터 일관성 유지
* NoSQL의 유형: 저장되는 데이터 구조에 따라서 나눔
| Key-Value Store | Column Family Data Store | Document Store | Graph Store |
| 유니크한 키 하나에 값 하나 get/put/delete로 처리 |
키 안에 (Column, Value) 조합 테이블기반,조인미지원 컬럼기반 |
데이터 타입이 Document document타입이 xml,json,yml |
그래프로 데이터를 표현 시멘틱웹과 온톨로지분야에서활용 |
| Redis, DynamoDB | HBase, Cassandra | MongoDB, Couchbase | Neo4j, AllegroGraph |
* CAP 이론: NoSQL은 CAP 이론을 기반으로 함
분산 컴퓨팅 환경은 Availability, Consistency, Partition Tolerance 3가지 특징 중 2가지만 만족할 수 있다는 이론
| Consistency | Availability | Partition Tolerance |
| 일관성 | 유효성 | 분산 가능 |
| 모든 사용자에게 같은 시간에 같은 데이터 제공 |
모든 클라이언트가 읽기&쓰기 가능해야 함 |
물리적 네트워크 분산환경에서시스템이 원활하게 동작해야 함 네트워크전송중 데이터손실상황이 생겨도 정상적으로 동작해야함 |
* ACID - NoSQL 에서 ACID요건을 완화하거나 제약하는 특징이있다
- 트랜잰션의 특징인 원자성(Atomicity), 일관성(Consistency), 독립성(Isolation) , 내구성(Durability)을 뜻한다.
* 빅데이터 저장 제품을 검토하기 위한 사용자 요구사항 분석 절차: 요구사항 수집 - 분석 - 명세 - 검증
* 저장방식 선정시 고려요소: 저장기술의 기능성, 분석방식 및 환경, 분석 대상 데이터 유형, 기존 시스템과의 연계
* 데이터 웨어하우스에서 데이터 처리 프로세스
1.ETL - 데이터 원천으로 부터 테이터를 추출 변환하여 적재하는 작업을 하며 데이터 웨어하우스로 보내기전에 수행
2. ODS - 데이터에 대한 추가 작업을 위해 다양한 데이터 원천 들로 부터 데이터를 추출및 통합한 데이터 베이스
- ODS 내 데이터는 비지니스 지원을 위해 타시스템으로 이관되거나, 보고서 생성을 위해 데이터 웨어하우스로 이 관된다
3.CDC - 데이터 백업이나 통합 작업을 할경우 최근 변경된 데이터를 대상으로 다른시스템으로 이동하는 처리기술
- 실시간 백업과 데이터 통합이 가능하여 24시간 운영 하는 업무에 활용
* ETL과 CDC 비교
* 공통된 목적은 원천 데이터를 DW, DM으로 적재
* ETL 특징 - 실시간이 아닌 정해진 시점의 완료된 데이터를 적재
* CDC 특징 - 실시간으로 적재
* 데이터 웨어하우스 특징 - 주체지향적, 통합적, 시계열적, 비휘발적
* 데이터 레이크 (Data Lake)
- 모든 가공되지않은 다양한 데이터를 저장하는 시스템 , 데이터 자장소
- 스키마와 상관없이 저장가능
- 데이터 사이언스에서 활용
