IT/머신러닝
머신러닝 교차검증(feat.싸이킷런)
unicorn
2022. 4. 19. 23:49
728x90
반응형
교차검증
- 교차검증을 하는 이유 - 과적합에 따른 성능저하 개선
- 과적합 이란? 모델이 학습데이터에만 과도하게 최적화 되어 실제 예측을 다른 데이터로 수행할경우 예측성능이 과도하게 떨어지는것, 고정된 학습/테스트 데이터로 평가를 하다보면 테스트 데이터에만 최적을 성능을 발휘하도록 평향된 모델을 유도 하는 경우가 생기고 결국 테스트 데이터에만 과적합 되는 학습 모델이 만들어져 다른 테스트 데이터가 들어오는 경우 성능이 저하

동일한 학습 데이터로 학습된 아래 3개의 모델을 비교해 보면? A. 모델 2가 실제와 가장 유사한 모델이라고 하였을 때, 모델 1은 너무 단순화되어 있고, 모델 3은 복잡성이 너무 높음
- 학습데이터를 다시 분할하여 학습 데이터와 학습된 모델의 성능을 일차 평가하는 검증 데이터로 나눔.
- 검증데이터를 바꿔가며 테스트를 해봄.
- 머신러닝은 데이터의 의존이 심하기 때문에 여러번 검증 데이터셋으로 학습과 평가를 수행하여 그결과에 따라 하이퍼 파라미터 튜닝등의 모델 최적화를 쉽게할수있다.
- 대부분 ML 모델의 성능은 교차 검증 기반으로 1차 평가후 최종적으로 테스트 데이터 세트에 적용해 평가하는 프로세스 - 학습 데이터를 다시 분할하여 학습 데이터와 학습된 모델의 성능을 일차 평가하는 검증 데이터로 나눔
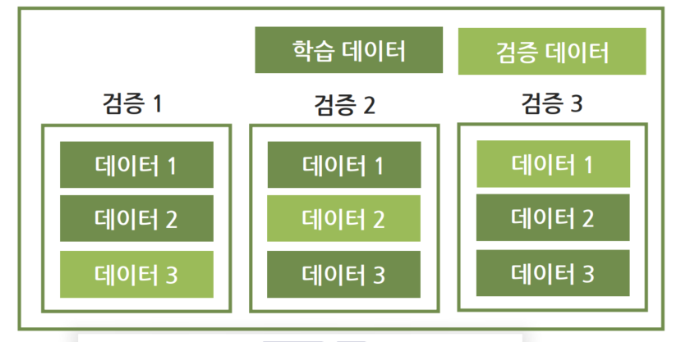
1.K 폴드 교차검증
- 가장보편적으로 사용 되는교차 검증 기법 , K 개의 데이터 폴드 세트를 만들어 K 번만큼 각 폴드 세트 에 학습과 검증평가를 반복 적으로 수행하는 방법
- 일반 K폴드
- Stratified K 폴드 - 불균형한 분포도(특정레이블값이 특이하게 많거나 매우적어서 값의 분포가 한쪽으로 치우치는 것을 의미 )를 가진 레이블 데이터를 집합을 위한 K 폴드 방식
- 학습 데이터와 검증데이터 세트가 가지는 레이블 분포도가 유사하도록 검증 데이터 추출 해야한다.
2.교차검증을 보다 간편하게 - cross_val_score()
- KFold 클래스를 이용한 교차 검증방법
- 폴드 세트설정
- For 루프에서 반복적으로 학습/ 검증 데이터 추출및 학습과 예측을 수행
- 폴드 세트별로 예측 성능을 평균하여 최종성능 평가
- estimator - 알고리즘 클래스
- X - 피처 데이터세트
- y - 레이블데이터세트
- scoring - 예측성능평가지표
- cv- 교차검증 폴드수
- 반환값 -cv 로 지정된 횟수만큼 scoring 파라미터로 지정된 성능지표로 결과값을 배열형태로 반환
- 분류 - stratifiedK폴드방식으로 레이블값 분포에따라 학습/ 테스트 세트 분할
- 회기 - Kfold 방식으로 분할
3.GridSearchCV
- - 교차 검증과 최적 하이퍼 파라미터 튜닝을 한번에
- 사이킷런은 GridSearchCV를 이용해 회귀나 분류 같은 알고리즘에 사용되는 하이퍼 파라미터를 순차적으로 입력하면서 편리하게 최적의 파라미터를 도출 할수 있는 방안을 제공 한다.
- 파라미터순차적용 횟수 * cv세트수 = 학습/검증 총수행횟수
- estimator - classifier, regressor, pipeline
- param_grid - key + 리스트 값을 가지는 딕셔너리 / estimator 의 튜닝을 위해 파라미터 명과 사용될 여러 파라미터 값 지정
- scoring - 예측성능평가지표(예 - 정확도 의경우 ‘accuracy’ 문자열)
- cv - 교차검증을 위해 분할되는 학습/테스트 세트의 개수
- refit - 디폴트 true / 가장최적의 하이퍼 파라미터 찾은 뒤 입력된 estimator 객체를 해당 하이퍼 파라미터로 재학습
728x90
반응형